Challenge
Prompt:
We are given a static webpage with some text saying:
BEEP BOOP. BOW DOWN TO OUR ROBOT OVERLORDS.
… and not much else. An obvious first step is to look at /robots.txt
This gives us:
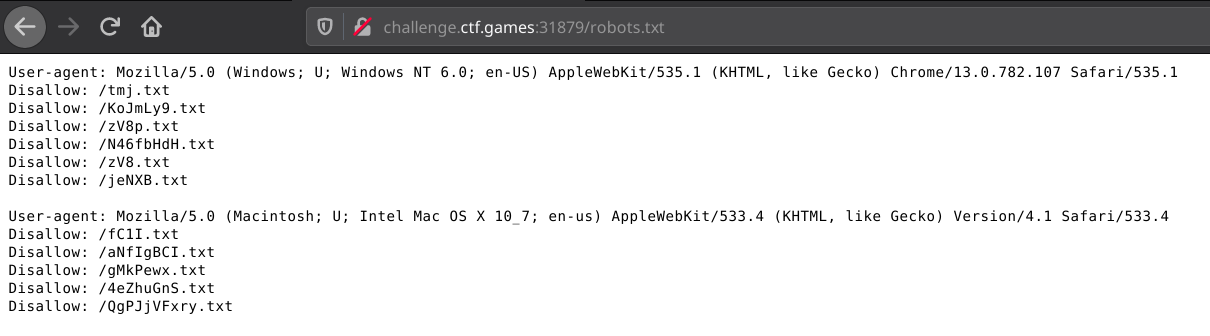
So seemingly it wants us to access the given .txt files with the provided user-agent headers.
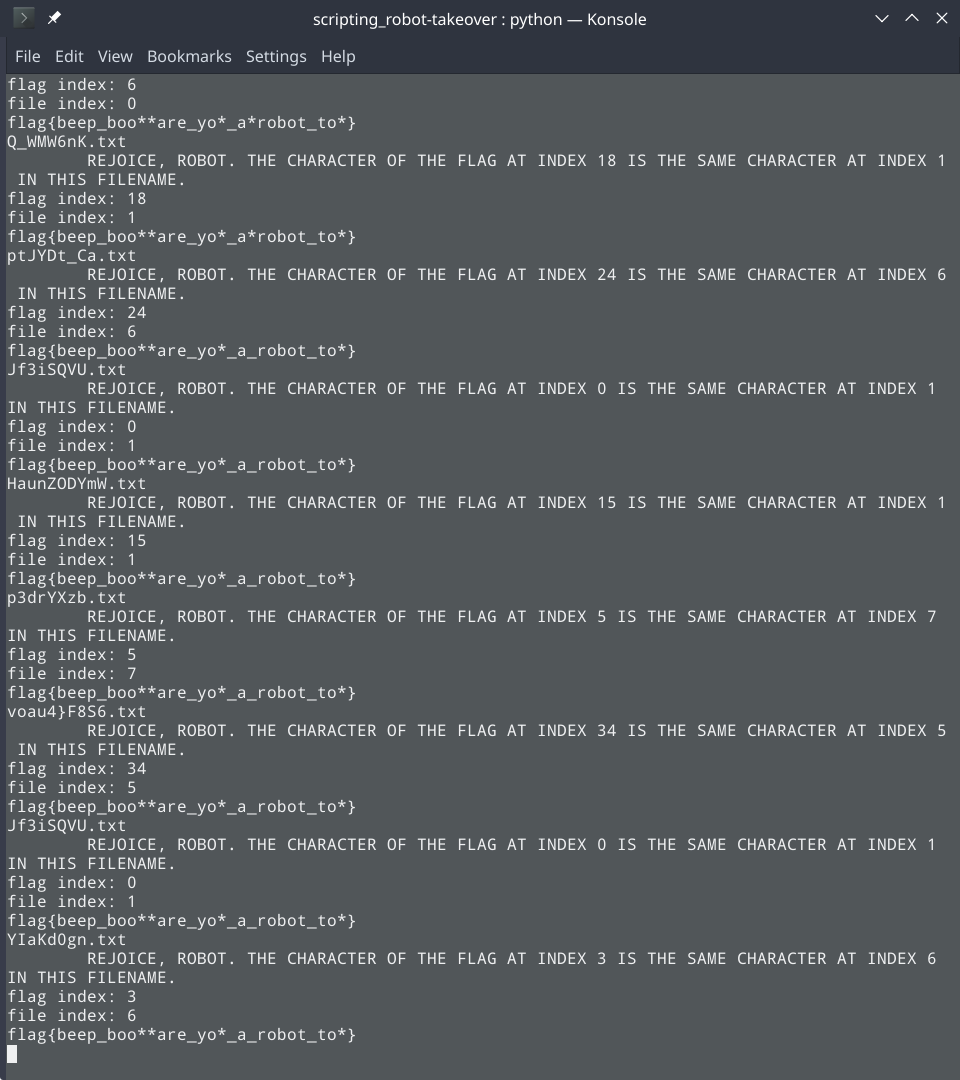
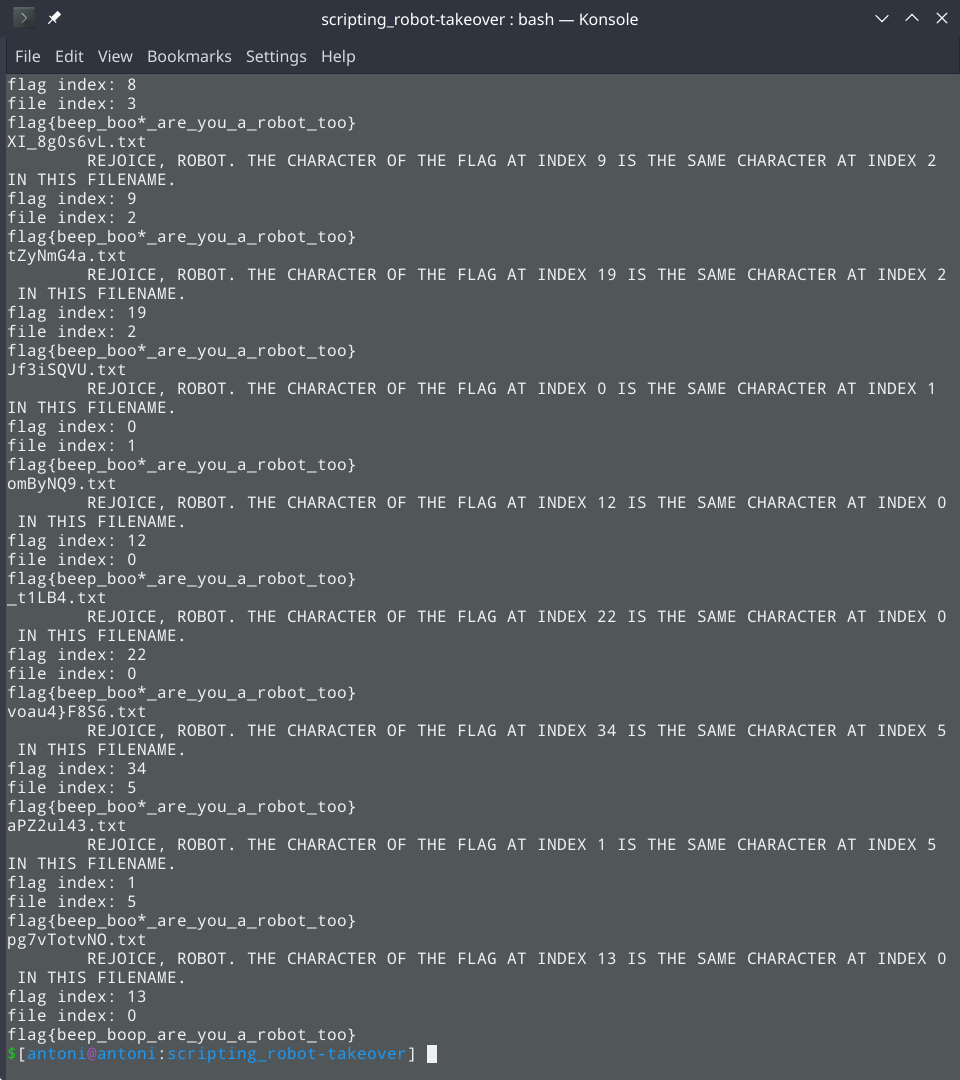
Using python requests to do this, we get several HTTP responses with text:
REJOICE, ROBOT. THE CHARACTER OF THE FLAG AT INDEX 24 IS THE SAME CHARACTER AT INDEX 6 IN THIS FILENAME.
Ok cool, we can get the flag by looking at the provided indices in the filename. Only problem was that only 4 of the endpoints returned a message like this, meaning we only had 4 characters of the flag.
After checking robots.txt again, I got this page:
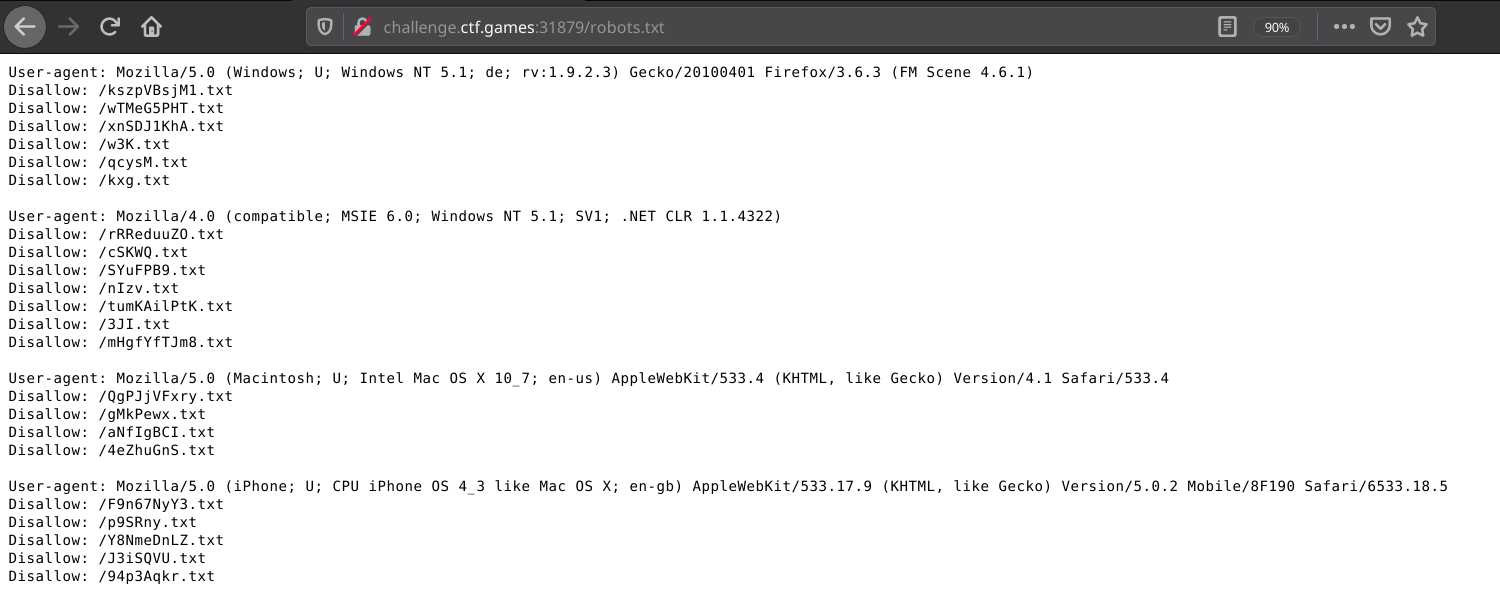
robots.txt gives us different content each time we refresh! This gives us a path to the flag: * request robots.txt * send GET requests to each endpoint with the given User-Agent header * build out the flag with the collected chars * repeat until we have the full flag
Script
I continued using Python requests to solve this challenge. In summary, my script makes continuous requests to /robots.txt, carves out the User-agent information and the corresponding endpoints, makes requests to those endpoints with the User-agent header set appropriately, checks if we get a response telling us a character in the flag, carves out the index of the character in the filename, carves out index of character in the flag, and finally, holds all found flag characters in a list.
import requests
import time
flag = ['*' for i in range(35)]
print(''.join(flag))
while '*' in flag:
robots_url = 'http://challenge.ctf.games:31879/robots.txt'
session = requests.Session()
r = session.get(robots_url)
chunks = r.text.split('\n\n')
for ch in chunks:
user_agent = ch.split('\n')[0].split('User-agent: ')[1]
endpoints = []
lines = ch.split('\n')[1:-1]
for l in lines:
endpoints.append(l.split('Disallow: ')[1])
headers = {'User-agent': user_agent}
for ep in endpoints:
url = f'http://challenge.ctf.games:31879{ep}'
try:
r = session.get(url, headers=headers)
except ConnectionError:
pass
if 'REJOICE' in r.text:
flag_index = int(r.text.split('AT INDEX ')[1].split(' ')[0])
filename_index = int(r.text.split('AT INDEX ')[2].split(' ')[0])
ep = ep[1:]
print(ep)
print('\t' + r.text)
print(f'flag index: {flag_index}')
print(f'file index: {filename_index}')
flag[flag_index] = ep[filename_index]
print(''.join(flag))
time.sleep(0.1)
Finally, I get to sit back and watch as the flag is formed: